HPC and HTC Concepts
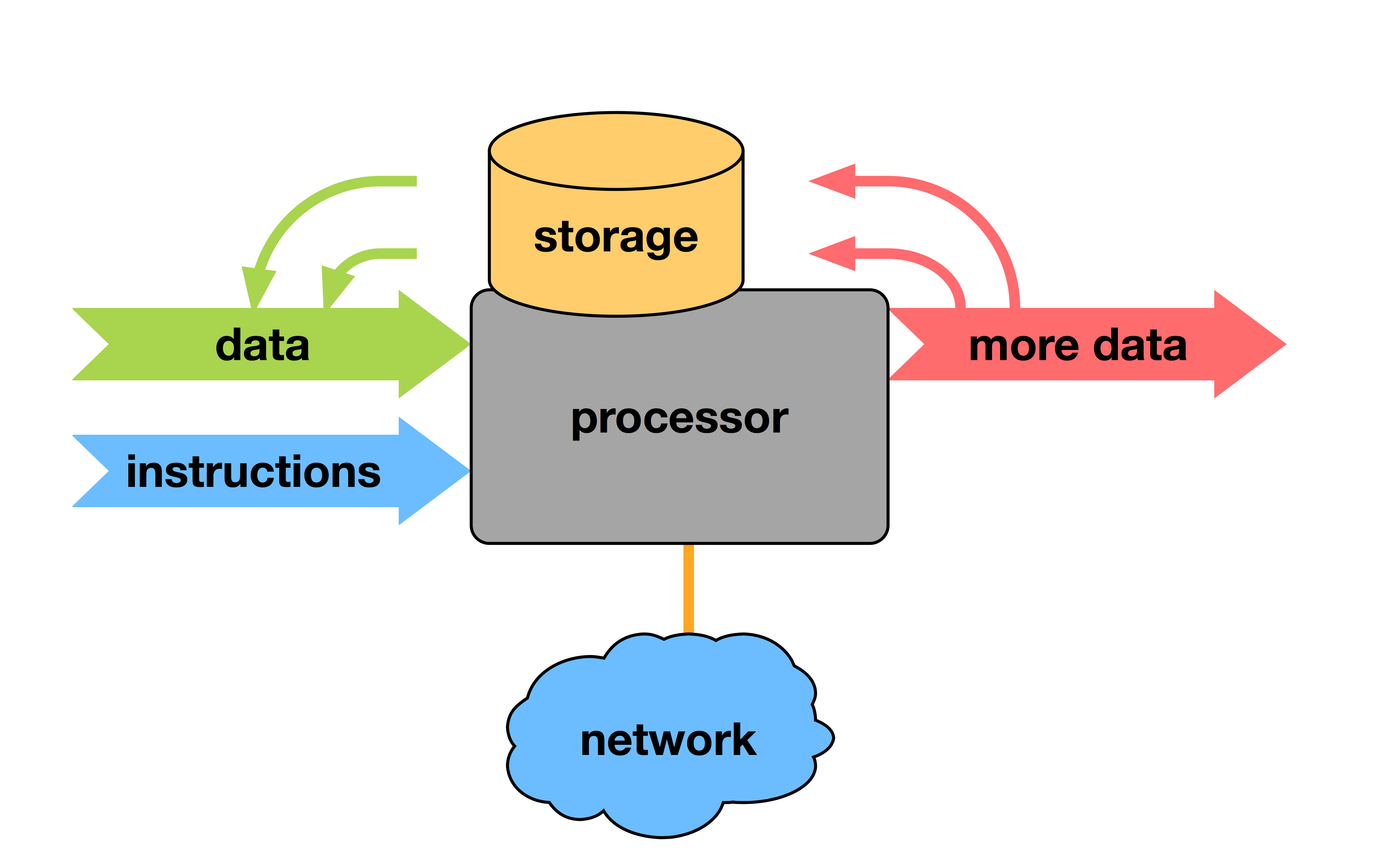
The Computer
Actual Rackable Server

Parallelism
Serial Process:
A process in which its sub-processes happen sequentially in time.
Only one sub-process is active at any given time.

Parallel Process:
- Process in which multiple sub-processes can be active simultaneously.

Parallel for Capability
Example: Large scale weather simulation
Detailed description for atmosphere too large to run on today's desktop or server PCs.
Multiple servers are needed to hold all grid data in memory.
Servers need to quickly communicate to synchronise work over entire grid
Communication between servers can become a bottleneck.
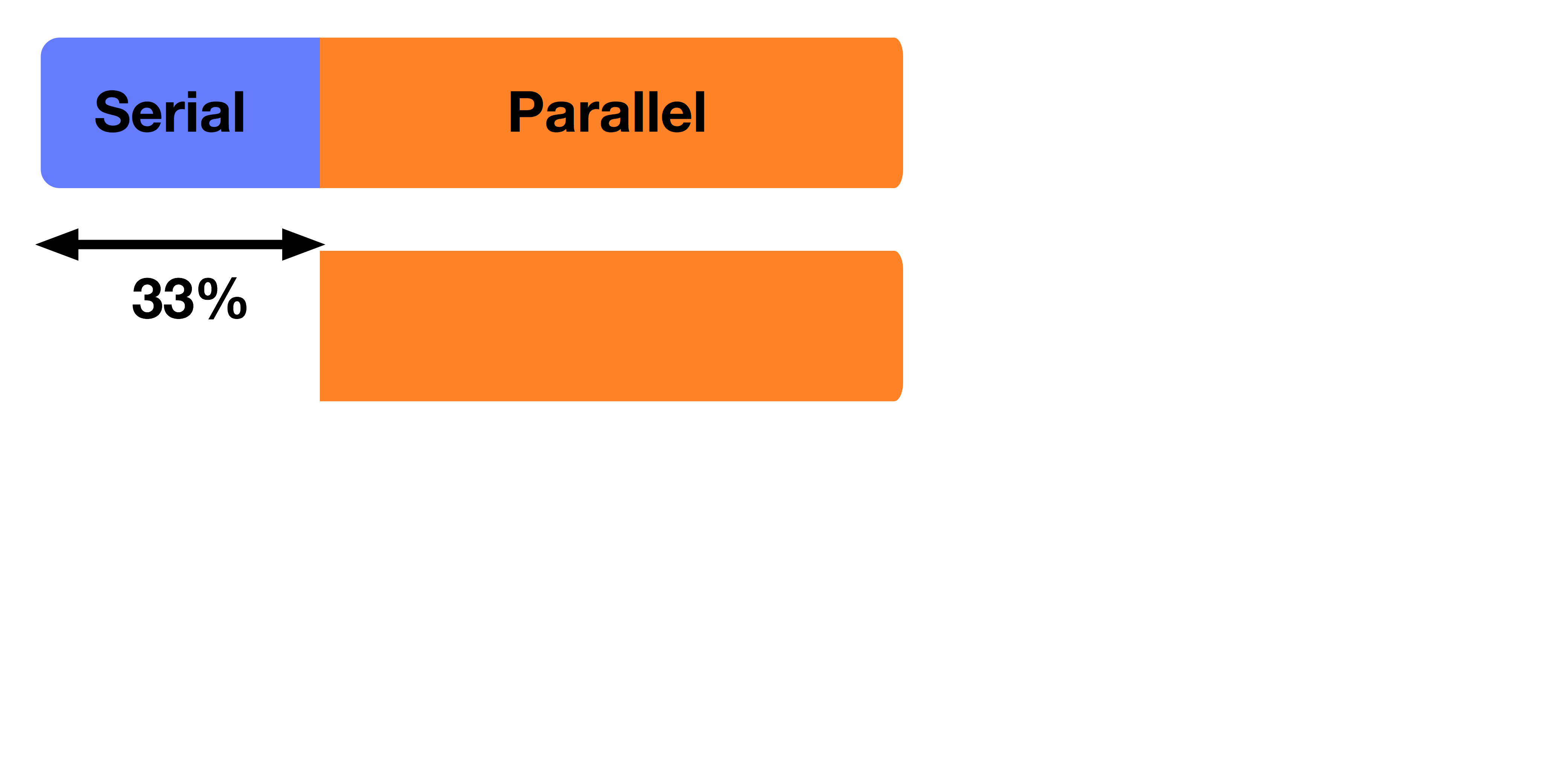
Amdahl's Law
1 Processor

Amdahl's Law
2 Processors
Amdahl's Law
10 Processors

Amdahl's Law
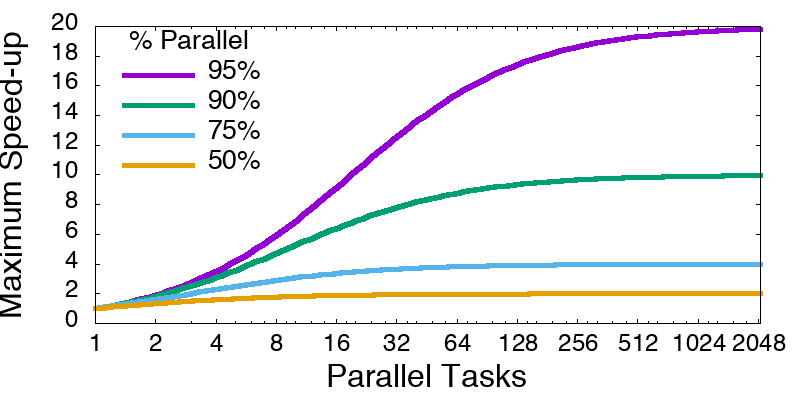
- If 95% of the program can be parallelized, the theoretical maximum speedup using parallel computing would be 20x, no matter how many processors are used.
SMP (Symmetric Multi-Processing)
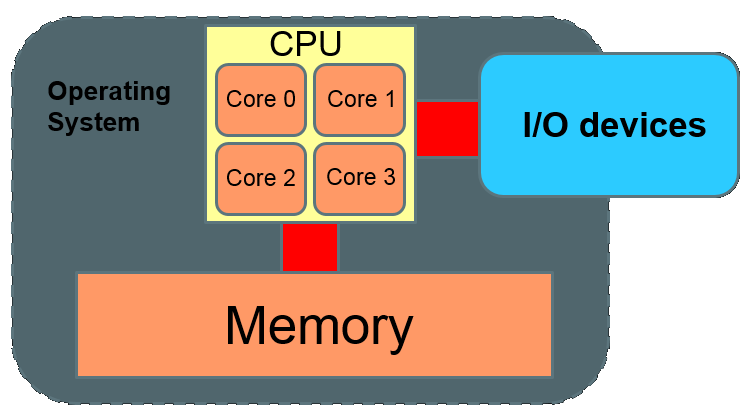
SMP (Symmetric Multi-Processing)
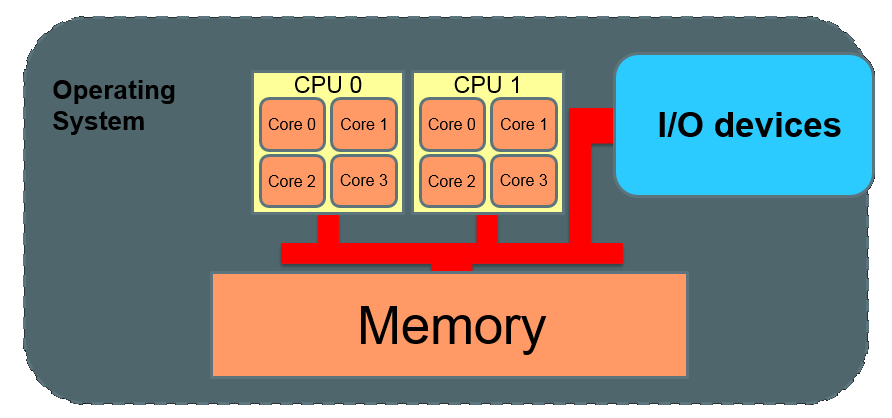
Beowulf Cluster
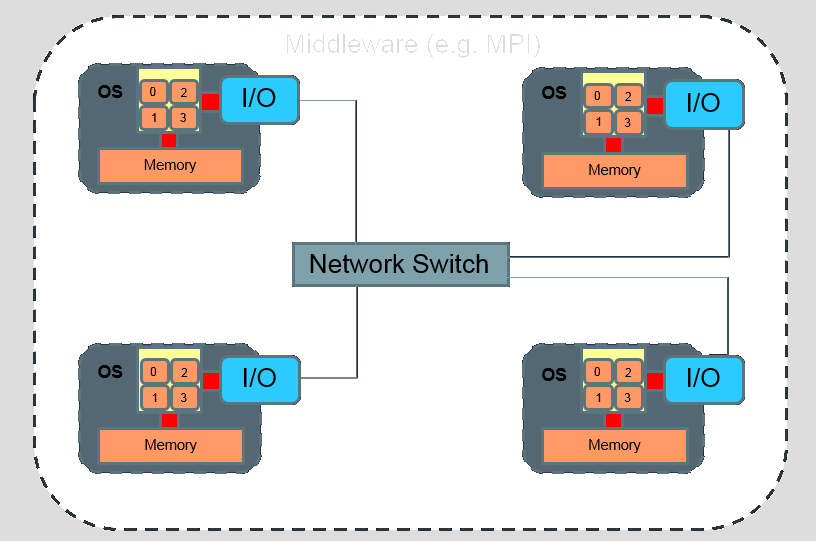
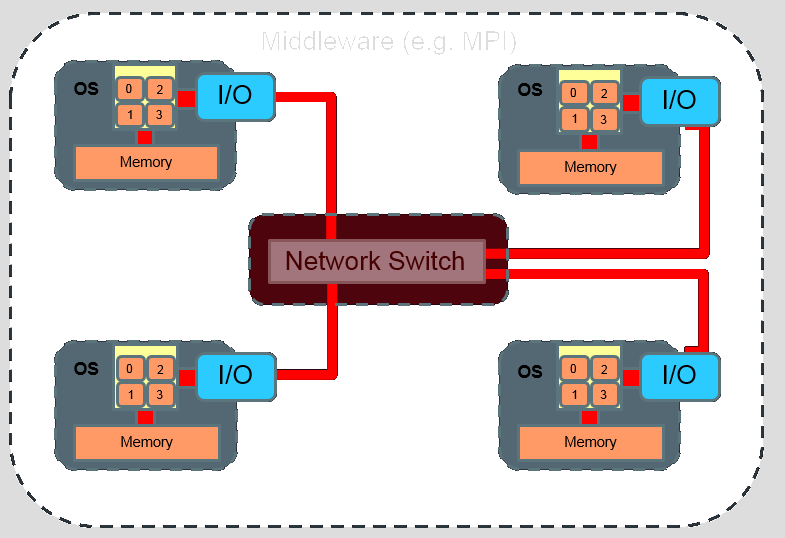
Infiniband Cluster
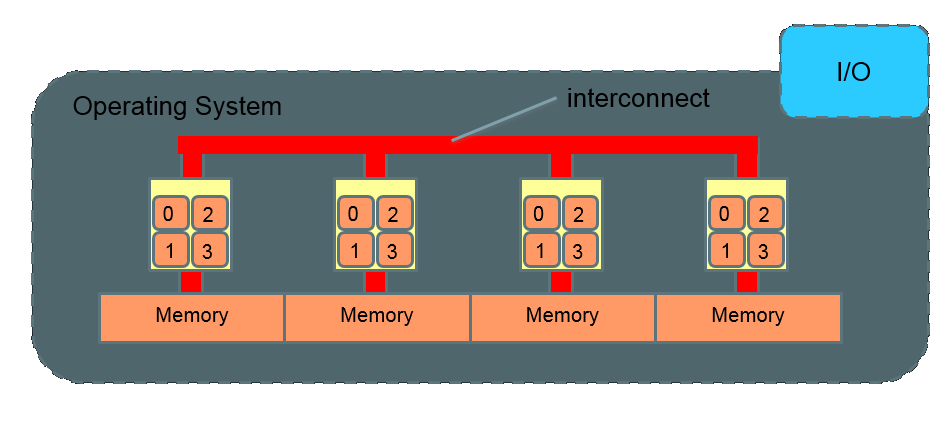
NUMA (Non-Uniform Memory Access)
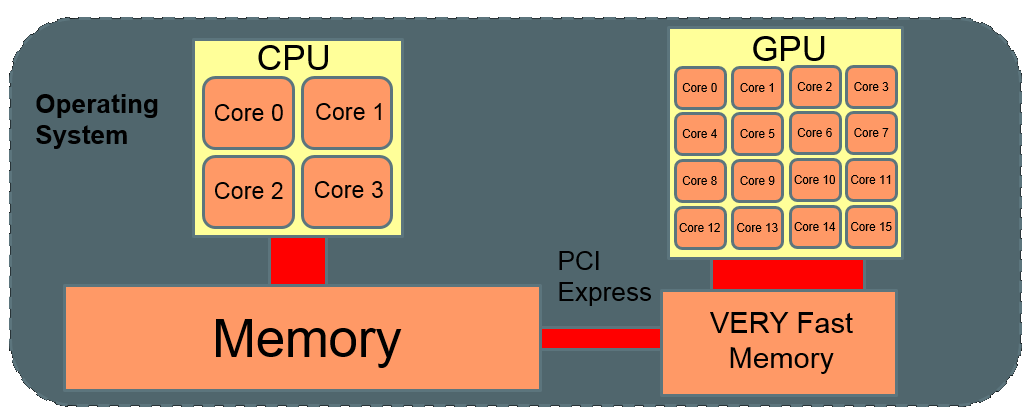
GPU accelerator
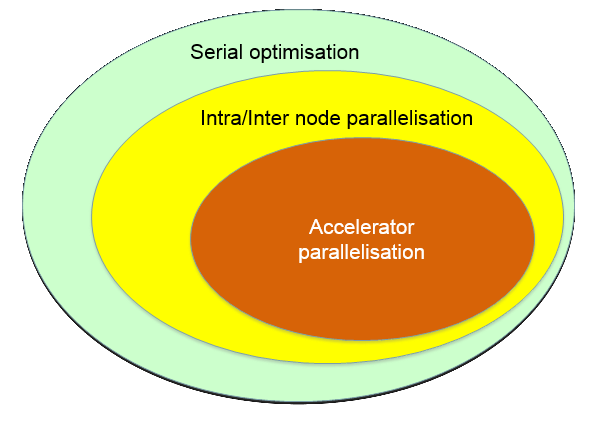
Only a subset of problems can be optimised
Not all problems can be parallelised
Not all parallel problems can be ported to accelerators
Applications
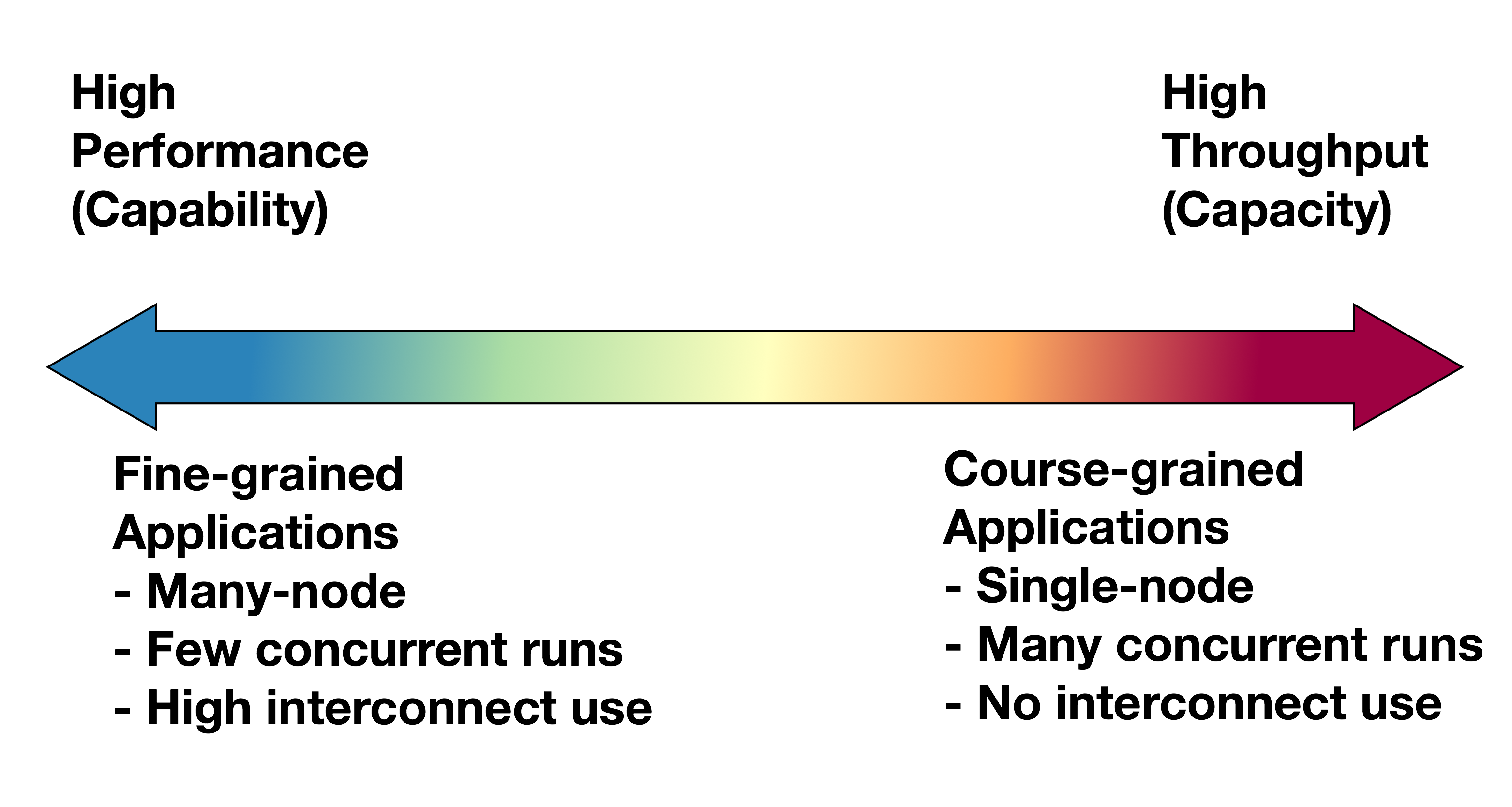
Overview
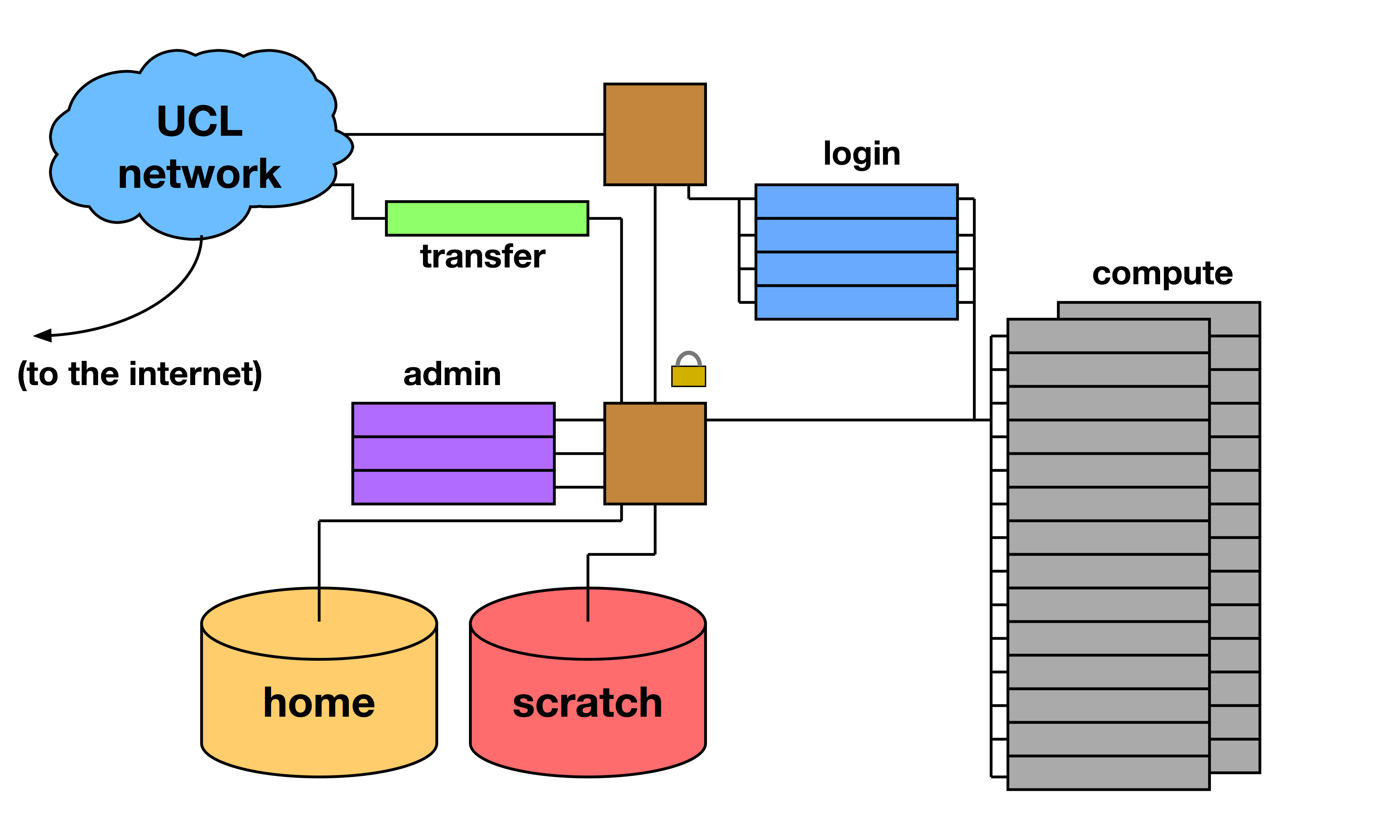
Generic Software stack
