
import urllib.request
import gzip
import pandas
data_url = "https://noaa-ghcn-pds.s3.amazonaws.com/csv.gz/1800.csv.gz"
with urllib.request.urlopen(data_url) as response:
with gzip.open(response, "rb") as f:
input_data = pandas.read_csv(
f, usecols=range(4), names=["station", "date", "quantity", "value"]
)
display(input_data.head())Lecture 22: Data pipelines

Centre for Advanced Research Computing
Introduction
Applying machine learning algorithms and approaches to real-world data involves a number of practical challenges. In this series of lectures, we will look at tools and ways of working that address questions like:
- How can I store and access large amounts of data remotely?
- How can I keep track of different versions of datasets?
- How can I share my results and make my analyses reproducible by others?
We’ll begin with the broader picture of how we handle data.
Learning outcomes
- Recognize that model training is just one part of machine learning workflows.
- Describe key typical stages of data pipelines.
- Identify the benefits of defining data pipelines programmatically.
- Explain the importance of the FAIR principles for data management.
Data preparation
Typically the data of interest will not be directly useable.
Before we can train any model, we first need to make sure that the data is available and properly formatted.
This can involve a number of steps:
- Accessing the data.
- Cleaning and other preprocessing.
- Transforming and generating features.
- Making the data available to the model.
The data is then ready to be used in our algorithm of choice.
Pipelines

This sequence of steps is sometimes called a data pipeline.
Another related term used to describe similar workflows is ETL: Extract-Transform-Load.
When possible, it is useful to perform these steps programmatically (through code) rather than manually.
Accessing data
If we haven’t collected the data ourselves, we will first need to access it. This can be done in a number of ways. For example:
- A colleague gives us a file.
- We connect to a web service that produces the data.
- We “scrape” a web page or other source to extract the data.
- We query a database for the particular data we want.
Accessing data
Sometimes we will need to combine more than one source to get the full set of data that we require.
We will talk more about databases in a subsequent lecture.
A common element in the above examples is that the data can exist in some remote location.
How we get it on our own computer will depend on the source, format and size of the data. However, this can often be done programmatically.
Example: Downloading climate data
Simple Storage Service (S3) is a storage service offered by Amazon Web Services (AWS).
Users can upload datasets which can be accessed by others.
As a running example we will look at an open dataset of historical global climate records.
Example: Downloading climate data
We download climate records for the year 1800 from a AWS S3 bucket noaa-ghcn-pds. The data is stored as a comma separated variable (CSV) file compressed using gzip.
| station | date | quantity | value | |
|---|---|---|---|---|
| 0 | EZE00100082 | 18000101 | TMAX | -86 |
| 1 | EZE00100082 | 18000101 | TMIN | -135 |
| 2 | GM000010962 | 18000101 | PRCP | 0 |
| 3 | ITE00100554 | 18000101 | TMAX | -75 |
| 4 | ITE00100554 | 18000101 | TMIN | -148 |
Preprocessing
Getting hold of the data you want to work with is only the first step. Sometimes this raw or preliminary data has to be changed. There are many reasons why:
- Data may contain errors.
- Dimensionality or size of dataset is too high.
- We want to focus only on a subset of interest.
- Raw data does not directly contain variables of interest.
- Some algorithms are negatively impacted by e.g. imbalances in class frequencies or extreme values.
Preprocessing
Preprocessing steps can include:
- Replacing values that are incorrect or cause problems.
- Filtering, subsampling (discarding samples) or supersampling (repeating samples).
- Removing outliers.
Aspects of this are often referred to as cleaning the data.
This is an important and often undervalued pipeline step.
These transformations can be performed manually, although tools like OpenRefine can simplify and automate the process.
Example: filtering climate records
Continuing with the climate data example, the dataframe input_data we loaded contains climate records for multiple different land-observation stations.
We might wish to fit a model to the daily extreme temperature records for a single station.
We therefore need to filter the input data to leave only the temperature measurements associated with this station.
Example: filtering climate records
Using station ITE00100554 (in Milan, Italy) as an example we can achieve this for example using the DataFrame.query method in Pandas.
| station | date | quantity | value | |
|---|---|---|---|---|
| 3 | ITE00100554 | 18000101 | TMAX | -75 |
| 4 | ITE00100554 | 18000101 | TMIN | -148 |
| 8 | ITE00100554 | 18000102 | TMAX | -60 |
| 9 | ITE00100554 | 18000102 | TMIN | -125 |
| 13 | ITE00100554 | 18000103 | TMAX | -23 |
Transforming
Cleaning brings you one step closer to useable data inputs for your model.
However, your analysis may rely on variables that are not directly present in the original data.
There is therefore a need for feature generation: extracting the variables of interest by combining existing ones.
Example: transforming to temperature range time series
The preprocessed_data dataframe we computed previously contains rows with individual TMIN and TMAX measurements (daily minimum and maximum temperatures in tenths of a degree Celsius) for each day in 1800.
If we wish to fit a regression model of the daily temperature range in degrees Celsius against the date we need to transform the data in the preprocessed_data dataframe accordingly.
Example: transforming to temperature range time series
| quantity | TMAX | TMIN |
|---|---|---|
| date | ||
| 1800-01-01 | -75 | -148 |
| 1800-01-02 | -60 | -125 |
| 1800-01-03 | -23 | -46 |
| 1800-01-04 | 0 | -13 |
| 1800-01-05 | 10 | -6 |
Example: transforming to temperature range time series
| temperature_range | |
|---|---|
| date | |
| 1800-01-01 | 7.3 |
| 1800-01-02 | 6.5 |
| 1800-01-03 | 2.3 |
| 1800-01-04 | 1.3 |
| 1800-01-05 | 1.6 |
Serving
The code you have written may expect to read in data in a particular format, such as a CSV file, or a collection of files.
The result of your preprocessing must therefore be made available in the same format.

Serving
Note that the result of this step need not be a file on your computer: you could choose to serve your data through, for example, a web service.
The important thing is that, at the end of this step, the data is ready to be fed into the model, matching what that code expects.
Serving
This preparation can often be done through a library. For instance, pandas offers several methods for writing out a data frame to a number of commonly-used formats:
Example: serving for scikit-learn
As seen in a previous lecture, scikit-learn models expect the training data for regression problems to be formatted as
- a features matrix, with each row corresponding to the (numeric) features for each training datapoint,
- and a target array, a one-dimensional array containing the target values for each training datapoint.
Example: serving for scikit-learn
Here we use the measurement dates converted to integer days of the year as the input features and the temperature ranges as the target values.
import matplotlib.pyplot as plt
X_train = transformed_data.index.day_of_year.array[:, None]
y_train = transformed_data.temperature_range.array
fig, ax = plt.subplots(figsize=(8, 3))
ax.plot(X_train, y_train)
ax.set(xlabel="Day of year", ylabel=r"Daily temperature range / $^\circ C$")
fig.tight_layout()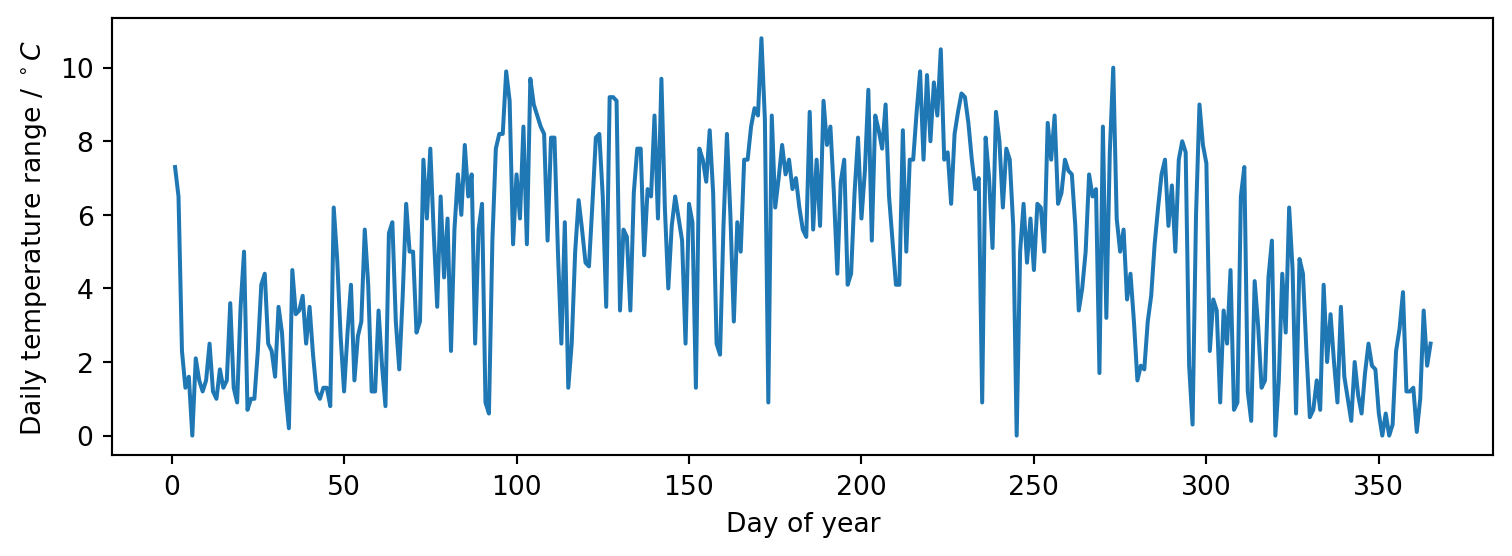
Model fitting
Once we have data in expected format we can fit a model using any of approaches seen in the previous lectures - for example scikit-learn or TensorFlow.
Note that both scikit-learn and TensorFlow themselves use data pipelines concept as an abstraction when building models - see for example the scikit-learn documentation for the Pipeline class.
Model fitting
When we refer to ‘a model’ we therefore are often actually referring to something that is itself a composition of multiple components, including steps we might consider as preprocessing or transforming.
The boundaries between the model and other stages in the pipeline we have described in reality may not always be as clear cut as in our simple flowchart.
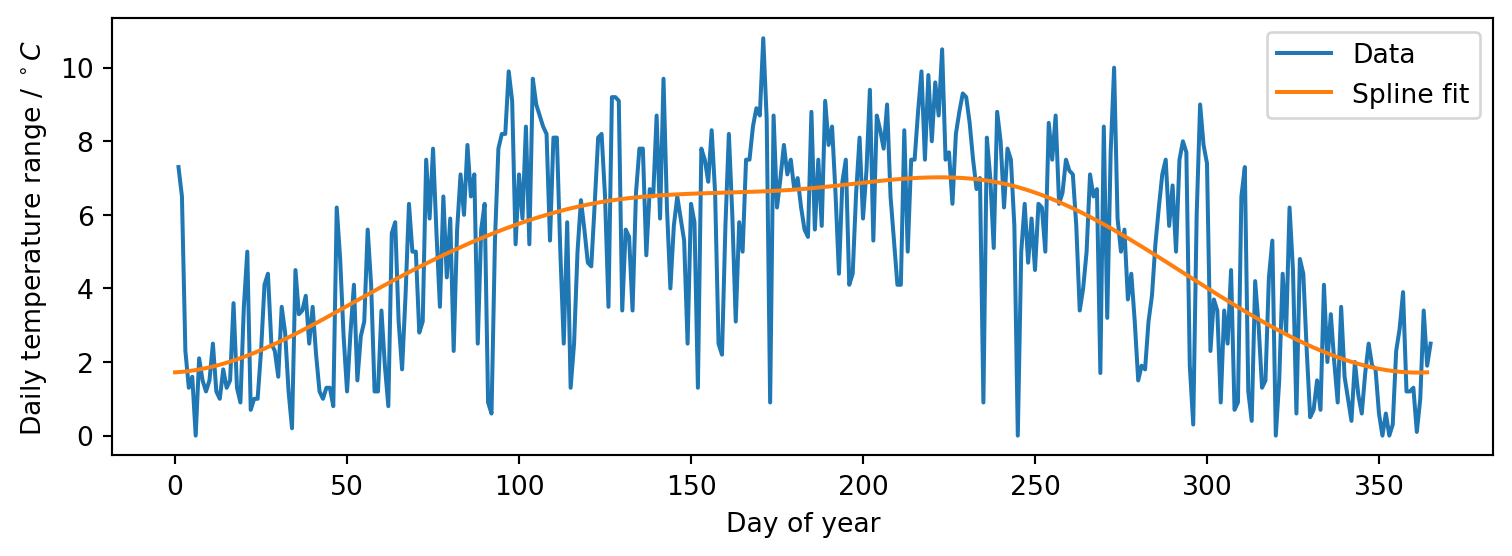
Example: fitting a periodic spline
We can fit a spline model using scikit-learn to smoothly interpolate our running example dataset.
As we have time series data of daily temperature ranges for a full year and expect the dominant trends to be seasonal, enforce that the fitted model is periodic.
We fit a cubic spline with seven knots at roughly bimonthly intervals so that we capture a smooth representation of the overall seasonal trends rather than the noisy daily variation.
Example: fitting a periodic spline
Pipeline(steps=[('splinetransformer',
SplineTransformer(extrapolation='periodic',
knots=array([[ 1. ],
[ 61.66666667],
[122.33333333],
[183. ],
[243.66666667],
[304.33333333],
[365. ]]))),
('ridge', Ridge())])In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Parameters
Parameters
Parameters
Example: fitting a periodic spline
We can visualise the fitted model’s predictions over the input range to check they look reasonable using matplotlib
Publishing
The lifecycle of data does not have to end when you feed it into a model!
You can even think of the model itself, and any analyses (e.g. predictions) you make based on it, as new data.
These can in turn be made available to support further research or other work.
You may want to consider uploading them to cloud storage (like S3) or a data repository like Zenodo.
Publishing data
When releasing your datasets, it is useful to put them in a standard format (such as CSV or JSON) that will be easy for others to read.
You should also include metadata that explains how the data was generated and what it contains.
FAIR principles
The FAIR principles are a guide for sharing research data outputs. They encourage you to ensure that your data is:
- Findable: users must be able to search for the data somewhere.
- Accessible: users must know how to access them (ideally automatically).
- Interoperable: the data can “work” together with other data or applications.
- Reusable: it is clear how to use the data, including its structure, format, and any conditions (licence).
Publishing models
Sharing the model itself is less straightforward, but there are still ways that you can make it available. You could:
- build an executable application that you can distribute for people to run;
- create a web service that people can call with their own data to get your trained model’s outputs;
- create a container (for use with e.g. Docker), a reusable image of your application and its dependencies;
- serialize the model and share it as a text file.
Model serialization
Serialization (converting the trained model code into a string which can be loaded and executed) is perhaps the simplest but is not always trivial.
Fortunately, Python’s pickle library can serialize a range of objects, including scikit-learn models, allowing you to store and share trained models as static files.
Example: serializing trained model
Pipeline(steps=[('splinetransformer',
SplineTransformer(extrapolation='periodic',
knots=array([[ 1. ],
[ 61.66666667],
[122.33333333],
[183. ],
[243.66666667],
[304.33333333],
[365. ]]))),
('ridge', Ridge())])In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Parameters
Parameters
Parameters
Summary
- Data needs to go through a number of steps before it can used in a model.
- Doing this process programmatically, not manually, leaves a record and facilitates repetition and verification.
- Remote access to data is becoming increasingly important as size grows.