Background: Freehand US Reconstruction
The aim of Freehand US reconstruction is to estimate the transformation between any pair of US frames in an US scan without any external tracker, and thus reconstruct 2D US images into a 3D volume (see Fig. 1).
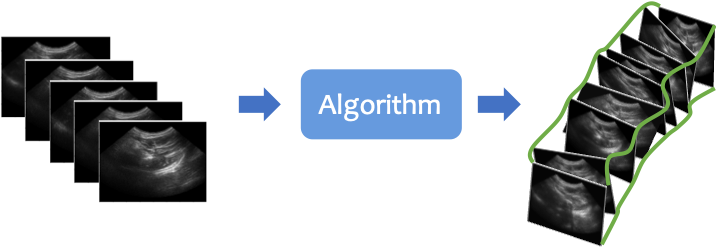
For an US scan \(\mathcal{S}\), image sequences comprising \(M\) 2D frames can be sampled as \(s_m=\{I_m\}, m=1,2,...,M\), where \(s_m \subseteq {\mathcal{S}}\) and \(m\) represents consecutively increasing time-steps at which the frames are acquired. Fig. 2 shows the relationship among three coordinate systems: the image coordinate system, the tracker tool coordinate system, and the camera coordinate system.
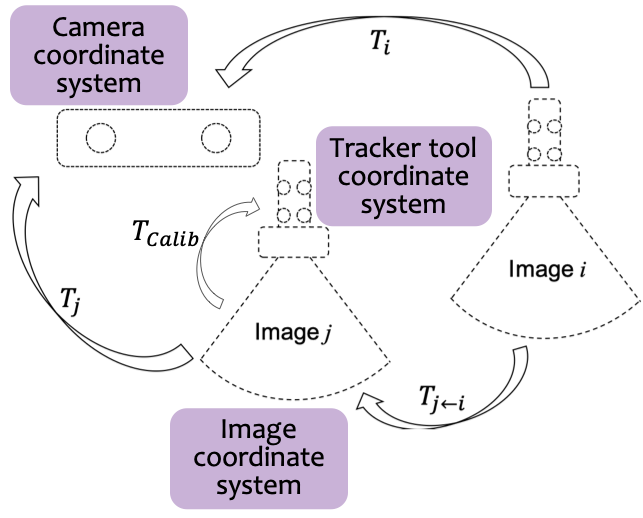
The rigid transformation from the \(i^{th}\) frame to the \(j^{th}\) frame (in mm), \(T_{j\leftarrow i}\), can be obtained using Eq. 1, where \(T_{j\leftarrow i}^{tool}\) denotes the transformation between \(i^{th}\) tacker tool to the \(j^{th}\) track tool and \(T_{rotation}\) represents spatial calibration from image coordinate system (in mm) to tracking tool coordinate system.
\(\begin{equation} T_{j\leftarrow i}= T_{rotation}^{-1} \cdot T_{j\leftarrow i}^{tool} \cdot T_{rotation} \tag{1} \end{equation}\)
In general, prior studies have formulated freehand US reconstruction as the estimation of the transformation between two frames in an US sequence. This estimation relies on a function \(f\), which serves as the core of freehand US reconstruction, as expressed in Eq. 2:
\(\begin{equation} T_{j\leftarrow i} \approx f(I_i, I_j) \tag{2} \end{equation}\)
Typically, adjacent frames are used in Eq. 2. The transformation from \(i^{th}\) frame to the first frame \(T_{1\leftarrow i}\) can be computed by recursively multiplying the previously estimated relative transformations, as shown in Eq. 3:
\(\begin{equation} T_{1\leftarrow i}= T_{1\leftarrow 2} \cdot T_{2\leftarrow 3} \cdots T_{i-1\leftarrow i} \tag{3} \end{equation}\)
Moreover, Eq. 3 demonstrates that estimation errors can propagate and accumulate throughout the chain, ultimately resulting in trajectory drift.
Reconstructing the 3D US volume and the trajectory of the US frames requires determining the position of each frame. The first frame is chosen as the reference. As a result, only the relative transformations with respect to the first frame are needed. For any pixel \(x\) in \(i^{th}\) frame with coordinates \(p_x\) in image coordinate system (in pixel) of frame \(i\), the coordinates in image coordinate system (in mm) of frame 1, \(P_x\), can be obtained using Eq. 4.
\(\begin{equation} P_x = T_{1\leftarrow i} \cdot T_{scale} \cdot p_x \tag{4} \end{equation}\) where \(T_{scale}\) denotes the scaling from pixel to mm.
Task Description
The algorithm is expected to take the entire scan as input and output two different sets of transformation-representing displacement vectors as results, a set of displacement vectors on individual pixels and a set of displacement vectors on provided landmarks. There is no requirement on how the algorithm is designed internally, for example, whether it is learning-based method; frame-, sequence- or scan-based processing; or, rigid-, affine- or nonrigid transformation assumptions. Details are explained further in Assessment.
Participant teams are expected to make use of the sequential data and potentially make knowledge transfer from US data with other scanning protocols, for example the dataset released in TUS-REC2024. The participant teams are expected to take US scan as input and output two sets of pixel displacement vectors, indicating the transformation to reference frame. The evaluation process will take the generated displacement vectors from their dockerized models, and produce the final accuracy score to represent the reconstruction performance, at local and global levels, representing different clinical application of the reconstruction methods.
We provide a baseline algorithm in this repo.
Difference between TUS-REC2025 and TUS-REC2024
From the results of TUS-REC2024, we observed that the reconstruction performance is dependent on scan protocol. In TUS-REC2025, we want to investigate the reconstruction performance on scans with a new rotating scanning protocol, with which the reconstruction performance may be further improved owing to its dense sampling of the area to be reconstructed. Compared with TUS-REC2024, TUS-REC2025 provides more data with new scanning protocol, and the previous released larger data with non-rotating scanning protocols is open to use. The new challenge aims to 1) benchmark the model performance on relatively small rotating data and 2) benchmark the model generalisation ability among different scanning protocols.