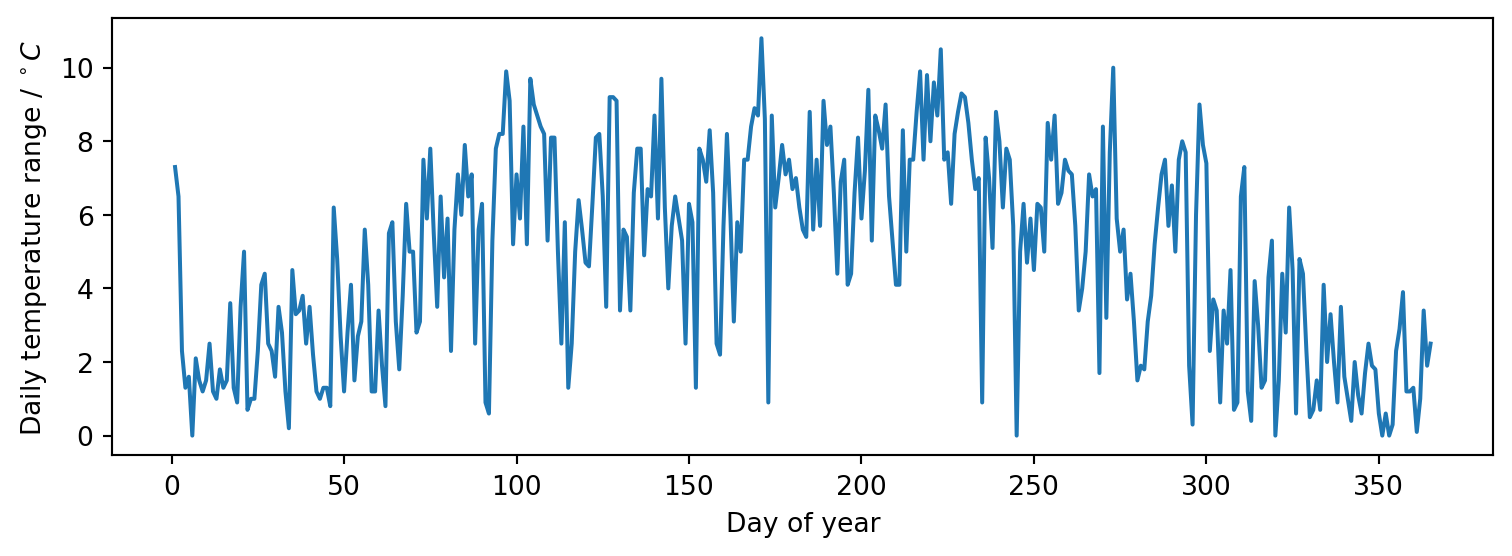
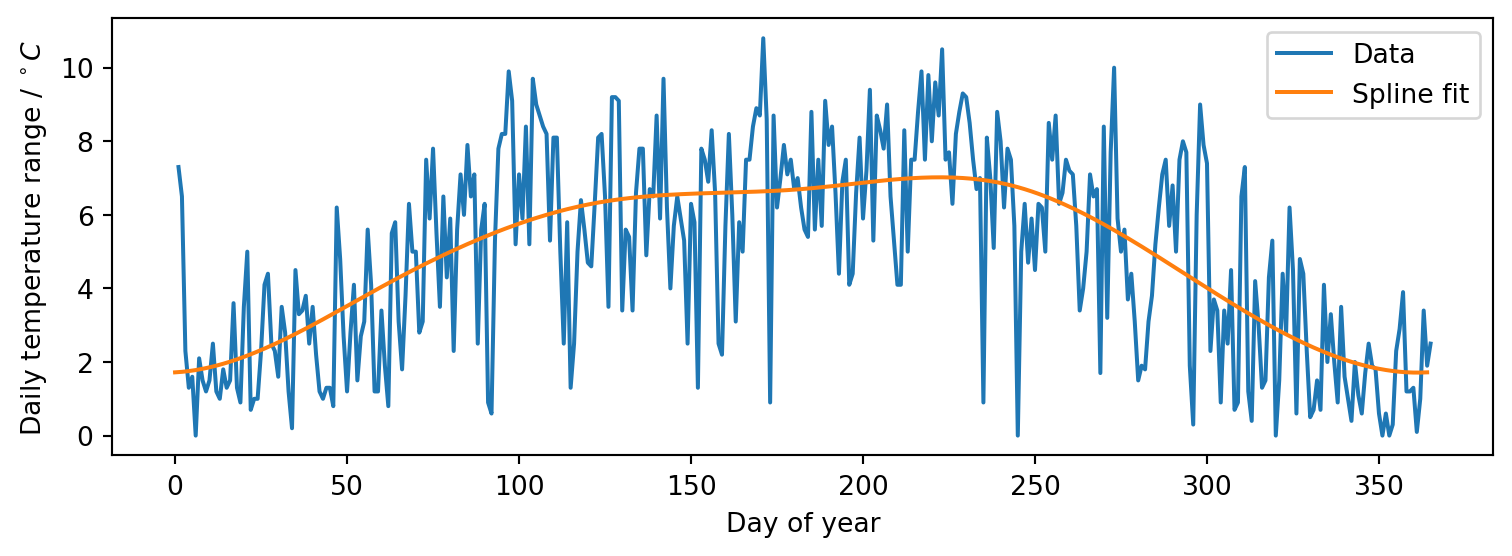
import urllib.request
import gzip
import pandas
data_url = "https://noaa-ghcn-pds.s3.amazonaws.com/csv.gz/1800.csv.gz"
with urllib.request.urlopen(data_url) as response:
with gzip.open(response, "rb") as f:
input_data = pandas.read_csv(
f, usecols=range(4), names=["station", "date", "quantity", "value"]
)
display(input_data.head())| station | date | quantity | value | |
|---|---|---|---|---|
| 0 | EZE00100082 | 18000101 | TMAX | -86 |
| 1 | EZE00100082 | 18000101 | TMIN | -135 |
| 2 | GM000010962 | 18000101 | PRCP | 0 |
| 3 | ITE00100554 | 18000101 | TMAX | -75 |
| 4 | ITE00100554 | 18000101 | TMIN | -148 |