 Close
Close

Estimated Reading Time: 45 minutes
Computational Complexity
Computational complexity is a major field in computer science, and we will only very briefly touch on the subject here. It is foundational in understanding computation as an idea, and underpins many areas of modern computing such as the theory of cryptography. For our purposes it will be enough to get a flavour of how we can study algorithms for their complexity properties, but you may wish to consult the reference texts for this week (or many other standard computer science texts) if you are interested in understanding complexity in a deeper and more rigorous way.
Complexity tells us how the time and space usage of solutions to a problem changes with respect to the size of its input.
Most commonly in numerical computing scenarios we are concerned with the time complexity of an algorithm, although there are occasions when you may have to worry about space complexity as well.
Intuitive Algorithm Analysis
When analysing an algorithm for its complexity, we are interested in how the time (or space requirements) of an algorithm scale as the input gets larger. We can define this notion in a formal way (see below!) but you can understand the key aspects of algorithmic performance based on a few intuitive concepts.
In terms of the input getting larger, this could mean:
- The size of a number $n$ for a function $f(n)$. A good example of this would be the time taken to find the prime factors of a number as the number gets larger.
- The number of elements in a container. For example, the time to sort a list of $n$ elements, or the time taken to look up a key-value pair in a map / dictionary.
- The number of dimensions of an $n$-dimensional space. For example in statistical sampling methods where we sample over many variables, we will be interested in how the algorithm performs as the number of dimensions increases.
-nThe size of a matrix: this example is a little unusual. Sometimes, particularly for a square ($n \times n$) matrix, this is expressed just by $n$, even though the number of elements in the matrix (and therefore the total size of the input) is actually $n^2$. On algorithms designed to work on non-square $n \times m$ matrices, you may have complexity in terms of both $n$ and $n$.
- Adding two square matrices of the same size together is usually described as $O(n^2)$ with $n$ referring to just one dimension of the matrix, whereas adding two lists of the same size is usually described as $O(n)$ with $n$ referring to the total number of elements, even though in both cases there is one operation per element of data. This difference is purely because of the way the input size is labelled in these two cases, so watch out for what people mean by $n$ when they tell you something is $O(g(n))$!
- The general matrix case for addition would usually be written $O(nm)$.
The “time” for an algorithm is based on the number of elementary steps that the algorithm has to undertake.
We generally write the complexity in terms of “Big-O” notation, e.g. $T(n)$ (the time as a function of $n$) is $O(f(n))$. For example if our function printed out the elements of a list, the number of steps we take is proportional to the number of elements in the list (linear scaling), so $T(n)$ is $O(n)$.
When talking about complexity, we only want to capture information about how the time or space scales as $n$ becomes large i.e. asymptotically as $n \rightarrow \infty$. As a result, we only care about dominant terms. Furthermore, we are only interested in the functional form of the scaling, not the absolute amount of time, so any constant factors are ignored.
- Any cubic is $O(n^3)$, any quadratic is $O(n^2)$ etc. regardless of lower order polynomial terms.
- $\log(n)$ is subdominant to $n$.
- Constant overheads (additive constants to the time) are ignored as they don’t scale with $n$.
- A function is $O(1)$ if it doesn’t scale with $n$ at all.
- $O(1) < O(log(n)) < O(n) < O(n log(n)) < O(n^2) < O(n^3) < O(2^n)$
- Algorithms whose time complexity is $O(p(n))$, where $p(n)$ is a polynomial, or better are called polynomial time algorithms.
We can also understand algorithms made of smaller parts, for example:
- If an algorithm calculates $f(n)$ which is $O(n^3)$ then $g(n)$ which is $O(n^2)$, then the complexity of the algorithm is $O(n^3)$ since calculating $g(n)$ will become subdominant.
- If we make $n$ calls to a function $f(n)$, and $f(n)$ is $O(g(n))$, then the complexity is $O(n g(n))$. For example, making $n$ calls to a quadric-scaling function would lead to a cubic, i.e. $O(n^3)$, algorithm.
- Nested loops and recursions are key areas of your program to look at to see if complexity is piling up!
- Recursions or other kinds of branching logic can lead to recurrence relations: the time to calculate a problem can be expressed in terms of the time to calculate a smaller problem. This recurrence relation is directly linked to the complexity:
- If $T(n) \sim 2 \times T(\frac{n}{2})$ then $T(n)$ is linear.
- If $T(n) \sim 4 \times T(\frac{n}{2})$ then $T(n)$ is quadric.
- If $T(n) \sim k + T(\frac{n}{2})$ for constant $k$ then $T(n)$ is logarithmic.
- See the Master Theorem for more on this if you’re interested!
- This is related to our intuition about how the time scales with $n$: if we know that a algorithm is $O(n^2)$ for example, we then know that as the input gets sufficiently large, the time taken to calculate the output will quadruple as $n$ doubles.
Algorithm Analysis: Sorting Algorithm Examples
Let’s take a look at two sorting algorithms and try to understand something about their complexity.
Insertion Sort
Insertion sort is one of the easiest sorting methods. We’ll sort from smallest to largest. We’ll show an out of place implementation because it is easier to visualise, but this can be performed in place (i.e. changing the elements of the list as we go instead of putting them in a new list).
-
It starts with an unsorted list, and in our case an empty buffer to place the elements into. This buffer will store the sorted list at the end and has the property that it is correctly sorted at every step. Elements are placed into the output list one by one. Since it starts empty, the first element can go straight in.
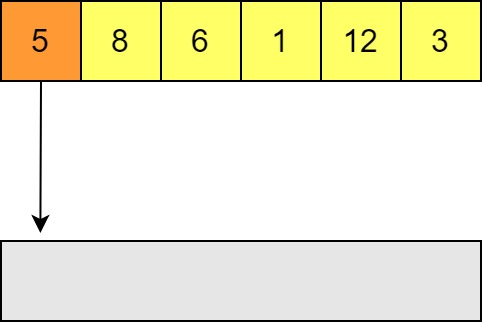
-
When placing the next element we compare with each element in the list in turn (starting with the end of the list) to see if it is smaller or larger. If the element is smaller (like here) then we can insert our element.
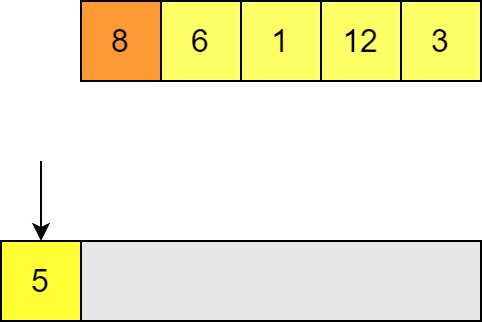
-
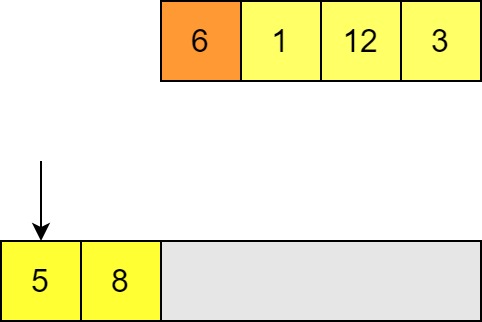
We then try to insert the next element, again comparing with the last element of the output list. If we find a value that is bigger than the one we want to insert then we need to move along to the next element.
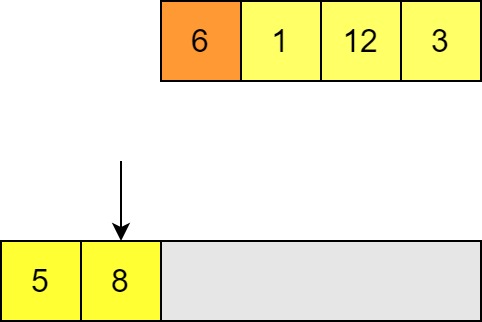
-
Once we’ve found one smaller we know where to insert the new element. All the elements in the output list to the right will need to be shifted along to make room.
-
In order to insert this in the right place, we have to move the larger element along one. (This would also mean moving along any elements to the right of this one!)
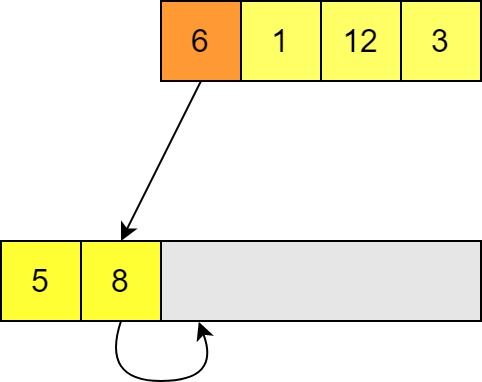
-
We can then insert our input element in the space and move on to the next element in the unsorted list. Again we compare until we find a smaller value; in this case we get all the way to the start of the list. Now all of the other elements need to be shifted along in order to insert this element.
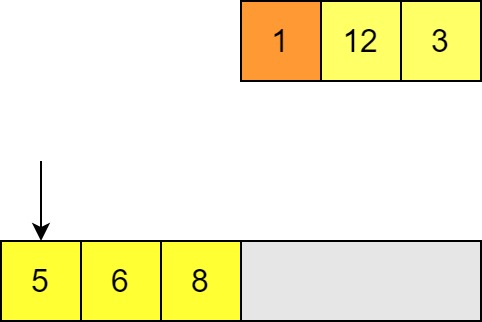
-
We continue until the all elements have been inserted into the output list. Since the output list is always sorted, as soon as we have inserted all the elements we are done.
What is the time complexity of this? Well, the performance of this algorithm depends on the pattern of the input! There are always $n$ insertions but:
- If the input is already sorted, then every step involves just one comparison. (In the case of an out of place algorithm, an insertion/copy; for an in place sort then this is skipped.) This is therefore linear in the size of the list i.e. $O(n)$.
- If the output is reverse sorted, then every step involves comparing with every element of the output list and shifting every element as well! The output list grows by one each time so this is proportional to $1 + 2 + 3 + … = \frac{n^2 + n}{2}$ and therefore $O(n^2)$.
These are the best case and worse case scenarios. In practice, the average case is still $O(n^2)$, and in general we are usually most concerned with our worst case complexity. Nevertheless, if you have nearly sorted data you can have good performance for an algorithm like this, and it is important to understand how your algorithms are impacted by patterns in the data that you are working on.
Merge Sort
Merge sort is a “divide and conquer” algorithm: the idea is that we can easily build a sorted list by merging two shorter sorted lists each containing half of the elements.
-
Merging two sorted lists is linear in the size of the list. At each step we compare the head of the two lists.
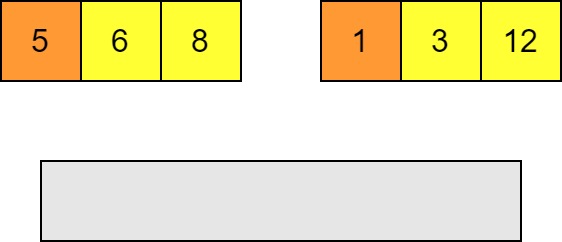
-
Whichever is smaller goes in the output list and then we make the next compare the next pair and insert the smaller and so on.
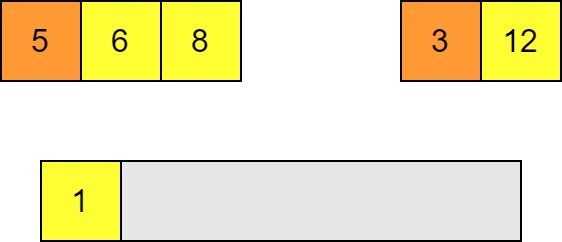
-
This is obviously done after $n-1$ comparisons and $n$ insertions so this part is $O(n)$ in the combined size of the lists.
Naturally a list with only one element is sorted, and so we can turn this into a recursive sorting algorithm using the list with one element as a base case.
-
The list is recursively divided until you have single elements. Then each of these is merged pair-wise to make sorted lists of size 2. (Merging all the lists involves $O(n)$ operations just as discussed above.)
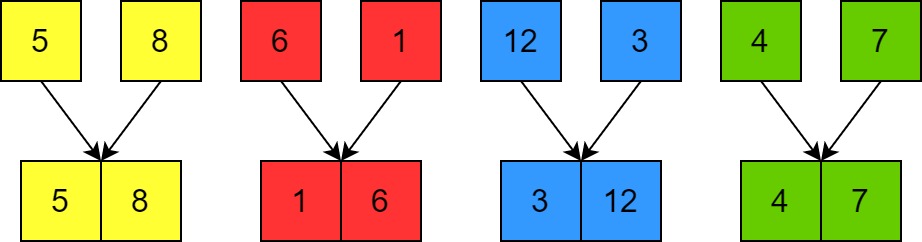
-
These lists are merged pairwise at each level of recursion until we have the fully sorted list.
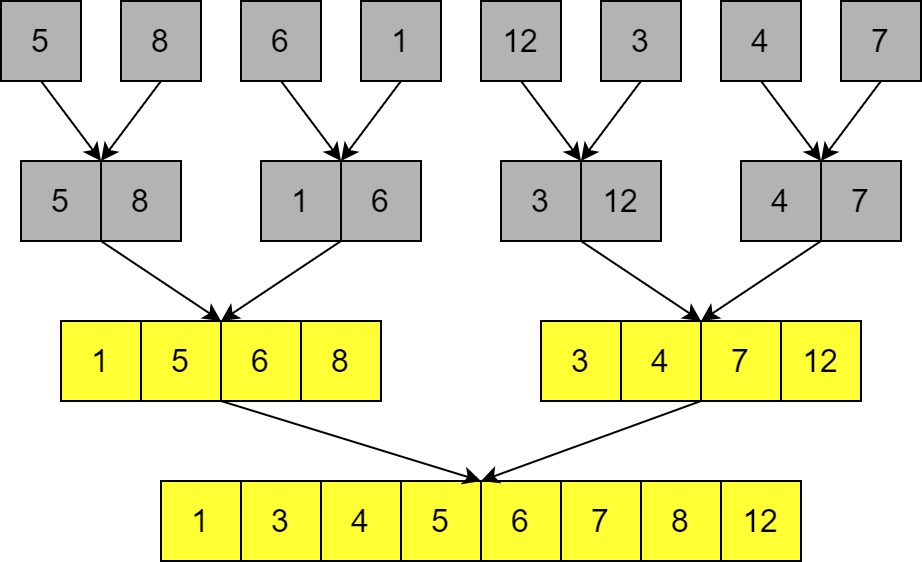
The complexity of this algorithm does not depend on any patterns in the list: a sorted, reverse sorted, or unsorted list still involves the same number of comparisons and merges.
Each round of merging takes $O(n)$ operations, so we need to know how many rounds there are. We split the list in half at each level of recursion, and we can only do this $\sim log_2(n)$ times before we have lists of size 1, therefore the total complexity is $O(n log(n))$.
- $O(n log(n))$ is actually optimal asymptotic behaviour for comparison sorting a list!
- $O(n log(n))$ is sometimes called “quasi-linear”.
- We can also approach this problem using a recurrence relation: $T(n) \sim O(n) + 2T(\frac{n}{2})$.
Comparison
- Merge sort has better asymptotic behaviour than insertion sort in the average and worst case.
- Insertion sort performance can depend strongly on the data.
- Merge sort has the same best, average, and worst case complexity so is very predictable.
- Merge sort has higher overheads due to all those recursive function calls.
- As a result, we know that merge sort will eventually beat insertion sort as long as $n$ becomes large enough, but insertion sort may provide better performance for small lists.
- Another popular algorithm is quicksort, which has $O(n log(n))$ behaviour in the average case (and is usually faster than merge sort), but $O(n^2)$ behaviour in the worst case. Selecting the best algorithms is not always obvious!
The Complexity of a Problem: Matrix Multiplication
As well as analysing the performance of a specific algorithm, one can look at the inherent complexity of a problem itself: with what asymptotic behaviour is it possible to solve a problem? When discussing the intrinsic complexity of a problem, the complexity of best solution we have provides an upper bound since we know we can do it at least that well, although we don’t know if we could do better. Getting more precise knowledge of the inherent complexity of many problems is an active area of research. (And if you can solve the $P=NP$ problem you get $1,000,000!)
Let’s take as an example the problem of matrix multiplication, an extremely common operation in scientific computing. What is the complexity of matrix multiplication? What algorithms are available to us and how do they get used in practice?
The Naïve Algorithm
We can define the elements of a product of two matrices as
$C_{ij} = A_{ik} B_{kj}$.
(We have used the summation convention.)
The simplest way to implement this is to iterate over $i$ and $j$, and for each element in the product matrix you perform a dot product between the $i$ row of $A$ and $j$ column of $B$ (which iterates over $k$).
- Assuming our matrices are $N \times N$:
- There are $N^2$ elements to do this for in the product matrix.
- Calculating each element requires $N$ multiplications.
- Total number of multiplications is therefore $N^3$.
- We can see this immediately because we have nested iterations over $i$, $j$, and $k$, each of which has $N$ values.
- Nothing else (e.g. memory read/writes) exceeds $N^3$ behaviour either. ($N^2$ writes, up to $N^3$ reads.)
So from a simple solution we can see that matrix multiplication is $O(n^3)$. It can’t be worse than asymptotically $n^3$, but it could be better, since we haven’t shown that it is bounded from below by $n^3$.
We can say that matrix multiplication must be bounded from below by $n^2$ (written as $\Omega(n^2)$ when it’s a lower bound; this is also defined formally below) since it needs to fill out $n^2$ values in the output matrix!
(Asymptotically) Better Matrix Multiplication
The most common improved matrix multiplication algorithm is the Strassen algorithm. We won’t go into the details of how the linear algebra works here, but we simply note:
- The Strassen algorithm divides each matrix into four (roughly equal) sub-matrices.
- Normally a matrix multiplication could be calculated using these sub-matrices by calculating 8 small matrix products. This wouldn’t save time: the naïve method is $O(n^3)$ and each matrix has size $\sim \frac{n}{2}$, so each sub-matrix multiplication is 8 times as fast, but there are also 8 matrix multiplications to do!
- By combining some of these sub-matrices through additions and subtractions (which are $O(n^2)$) we can actually express the output matrix with just 7 small matrix products! (Again, some addition and subtraction required to build the output matrix after the products are calculated.)
- The additions and subtractions are negligible because there are a fixed number and they are $O(n^2)$ and therefore sub-dominant.
- Doing this recursively for sub-matrices as well leads to an algorithm which is $\sim O(n^{2.8…})$.
- Extra: To prove this you can write the number of operations as a recurrence relation $T(n) = 7T(\frac{n}{2}) + O(n^2)$ and apply the Master Theorem. Again the recommended texts for this week are a good place to start!
This may seem like a small gain, but it becomes increasingly important as matrices get large, and large matrix multiplication can be a bottleneck for many numerical codes!
We should bear in mind:
- This algorithm has more overheads than normal matrix multiplication. Asymptotic improvement does not mean it’s better for all sizes of problems! For small matrices, the additional overheads of Strassen multiplication make it slower than the straightforward method. As a result, most implementations actually transition to regular matrix multiplication when the sub-matrices get to be small enough in size that this becomes more efficient. This kind of behavioural change is very common when optimising for performance.
- The Strassen algorithm is less numerically stable than the simple method, although not so much so as to be an issue in typical applications. This is again a common trade off with code optimised for speed, and something to bear in mind if you know that you have to deal with unstable edge cases.
So is this the best known performance for matrix multiplication? Not quite! The best known algorithm for matrix multiplication is $\sim O(n^{2.37…})$, but this is unusable in practice. It is an example of what is called a galactic algorithm; algorithms which have better asymptotic behaviour, but whose overheads are so large that they actually perform worse for any input that could physically fit on any plausible machine. It is a good reminder that asymptotic behaviour isn’t everything!
Formal Definition: “Big O” Notation
When writing software much of our reasoning can be done using the kind of intuitions outlined above. In order to have a more thorough grounding in these concepts and why this notation is so useful for classifying algorithms and problems, it is useful to look at how we define the scaling of functions in a more formal way. The definition of “Big-O” notation is as follows:
$f(n)$ is $O(g(n))$ if and only if there exists some minimum value $n_0$ and some constant $\alpha$ such that whenever $n > n_0$, $\mid f(n) \mid \le \alpha g(n)$.
Let’s break down what this means:
- A function $f(n)$ is $O(g(n))$ if, as $n$ tends to infinity, $f(n)$ is bounded from above by $g(n)$ multiplied by an arbitrary constant.
- Because we only require that the comparison holds for all inputs larger than some arbitrarily large value $n_0$, we are looking at asymptotic behaviour. We say that $g(n)$ is an asymptotic upper bound on $f(n)$.
- Practically speaking this means we are generally only interested in leading terms. For a quadratic $an^2 + bn + c$, the linear and constant terms will always be overwhelmed by the quadratic term in the asymptotic case, and so are irrelevant. All quadratics are $O(n^2)$, regardless of the values of $a$, $b$, and $c$ (as long as $a \ne 0$).
- For example: $\mid an^2 + bn + c \mid \le (a+1)n^2$ will always hold for $n$ large enough so that $n^2 > \mid bn + c \mid$, which we know must exist for any coefficients $b$ and $c$.
- We have an arbitrary constant factor $\alpha$, so constant factors in $f(n)$ are irrelevant. $n^2$ and $50n^2$ are both $O(n^2)$. We are only interested in the way that the output scales, not the actual size. This will be a very important point to remember when applying algorithms in practice!
- For this definition to make sense and be useful, the function $g(n)$ must be asymptotically non-negative.
- This can also be written treating $O(g(n))$ as the set of functions that asymptotically bounded by $g(n)$.
- $f(n) \in O(g(n)) \iff \exists m, \alpha . \forall n > m . \mid f(n) \mid \le \alpha g(n)$.
- Texts can vary quite a bit in notation e.g. $f(n) \in g(n)$ or $f(n) = g(n)$ (a bit of an abuse of notation since it is not an equivalence relation, but fairly common in practice), and in mathematical formality.
We can also write $f(n)$ is $\Omega(g(n))$ if $g(n)$ is an asymptotic lower bound of $f(n)$. This is a reciprocal relationship with $O(n)$ i.e.
$f(n)$ is $O(g(n))$ if and only if $g(n)$ is $\Omega(f(n))$.
There is also a stronger condition:
$f(n)$ is $\Theta(g(n))$ if and only if $f(n)$ is $O(g(n))$ and $g(n)$ is $O(f(n))$.
- This means that $g(n)$ is an asymptotically tight bound on $f(n)$, because as $n$ tends to infinity $f(n)$ is bounded by a constant multiple of $g(n)$, and $g(n)$ is bounded by a constant multiple of $f(n)$.
- Put another way, there are two constants $\alpha$ and $\beta$ for which, as $n$ tends to infinity, $f(n) \ge \alpha g(n)$ and $f(n) \le \beta g(n)$. As such, $f(n)$ is bounded from above and below by multiples of $g(n)$.
- $f(n)$ is $\Theta(g(n))$ if and only if $f(n)$ is $O(g(n))$ and $f(n)$ is $\Omega(g(n))$.
This relationship is symmetric:
$f(n)$ is $\Theta(g(n))$ if and only if $g(n)$ is $\Theta(f(n))$.
Asymptotically tight bounds are particularly useful for understanding the behaviour as a function scales. Take our quadratic example from before: $an^2 + bn + c \in O(n^2)$ is clearly true, but looking at the definition of $O(g(n))$ we can also say that $an^2 + bn + c \in O(n^3)$, since $n^3$ is asymptotically larger than any quadratic function and therefore acts as an upper bound. The same would be true of many functions which grow faster than quadratics! Likewise $O(n^2)$ includes anything that grows slower than a quadratic, such as a linear function. To say that our quadratic is $\Theta(n^2)$ is much stricter, as it says that our function grows as fast as $n^2$ and no faster than $n^2$ (up to multiplicative constants).
Why use Big-O Notation for Algorithms and Computational Problems?
For algorithmic analysis, the functions that we are interested in are the time and space usage of an algorithm as a function of its input size.
- Time usage is usually understood in terms of the number of “steps” that an algorithm needs to reach a result. How exactly that translates into time in the real world depends on how long each kind of operation takes to do (e.g. memory read, comparison, additions etc.), but these are multiplicative factors.
- Note that sometimes things which might appear to be a simple step are more complex. For example, if performing additions with arbitrary precision integers then the time it takes to perform the addition will vary with the size of the number! If using fixed precision then this is not an issue because you know that e.g. a standard
intis 4 bytes, and so even if the addition is optimised in some way to add smaller numbers quicker they are still bounded by the time it would take to operate on 4 bytes.
- Note that sometimes things which might appear to be a simple step are more complex. For example, if performing additions with arbitrary precision integers then the time it takes to perform the addition will vary with the size of the number! If using fixed precision then this is not an issue because you know that e.g. a standard
- Space is usually a bit easier to understand as we can reason more directly about the amount of information that we have to store.
- When analysing space complexity we do not include the input itself, just any memory that must be allocated for working on.
- What we mean by the “input size” can be ambiguous. Traditionally it can be more rigorously defined in terms of tape size on a Turing machine (which we we won’t have time to cover!) or bits on a computer, but in practice people may typically reason with the kinds of intuitive values mentioned before which would correspond with the input size.
Big-O, $\Omega$, and $\Theta$ all capture information about algorithm performance without knowing too much detail about how it is physically performed on a computer: things like the exact amount of time for particular operations, the differences in how memory is divided up for reading and writing, and so on get absorbed into multiplicative factors or additive overheads. Big-O notation captures something more fundamental about the way that problems scale. Even things like modern CPUs doing multiple arithmetic operations in parallel don’t affect the computational complexity of an algorithm, since there are still a fixed number of operations than can happen concurrently and therefore this can’t contribute more than a constant factor.
Take for example a trivial summation example:
double SumVector(const vector<double> &v)
{
double sum = 0;
for(auto &x : v)
{
sum += x;
}
return sum;
}
- We’re interested here in how we scale with the number of elements in the list, so we’ll call this $n$.
- There is one addition operation for each element in the list, so $n$ operations total. Time complexity is $\Theta(n)$ i.e. linear.
- Regardless of the size of the list, we only allocate one
double(sum) for this function, so the space complexity is $\Theta(1)$ i.e. constant.
For algorithmic analysis we can often determine asymptotically tight bounds because we know exactly how an algorithm will behave.
Summary of Complexity in Practice
- It’s good to be aware of the complexity bounds on problems and algorithms that you will be working with, like matrix multiplication, matrix inversion, data lookups in different kinds of structures etc.
- Functions in the standard C++ library will often have known complexity given in the documentation, for example accessing an ordered map is $O(log(n))$ and accessing an unordered map is $O(1)$ in the average case and $O(n)$ in the worst case.
- Be aware when you are writing code of how your program scales. Think about things like nested loops and recursions and how their contributions combine.
- Algorithms with high complexity can become bottlenecks for your programs if their inputs become large.
- More efficient algorithms can often be a trade-off between time and accuracy or other desirable properties.
- Algorithms with good asymptotic performance often perform less well on small problems; don’t waste time or sacrifice accuracy to use these kinds of methods on small data where they won’t benefit!
- Some algorithms have good average case complexity but very bad performance in special cases. Make sure that you’re aware of any patterns that you expect in your data and that your chosen algorithm is not impacted by them.
- Well implemented methods often switch between algorithms depending on the size and nature of the data input to get the best performance.